- エコシステム
- クイック ファインダー

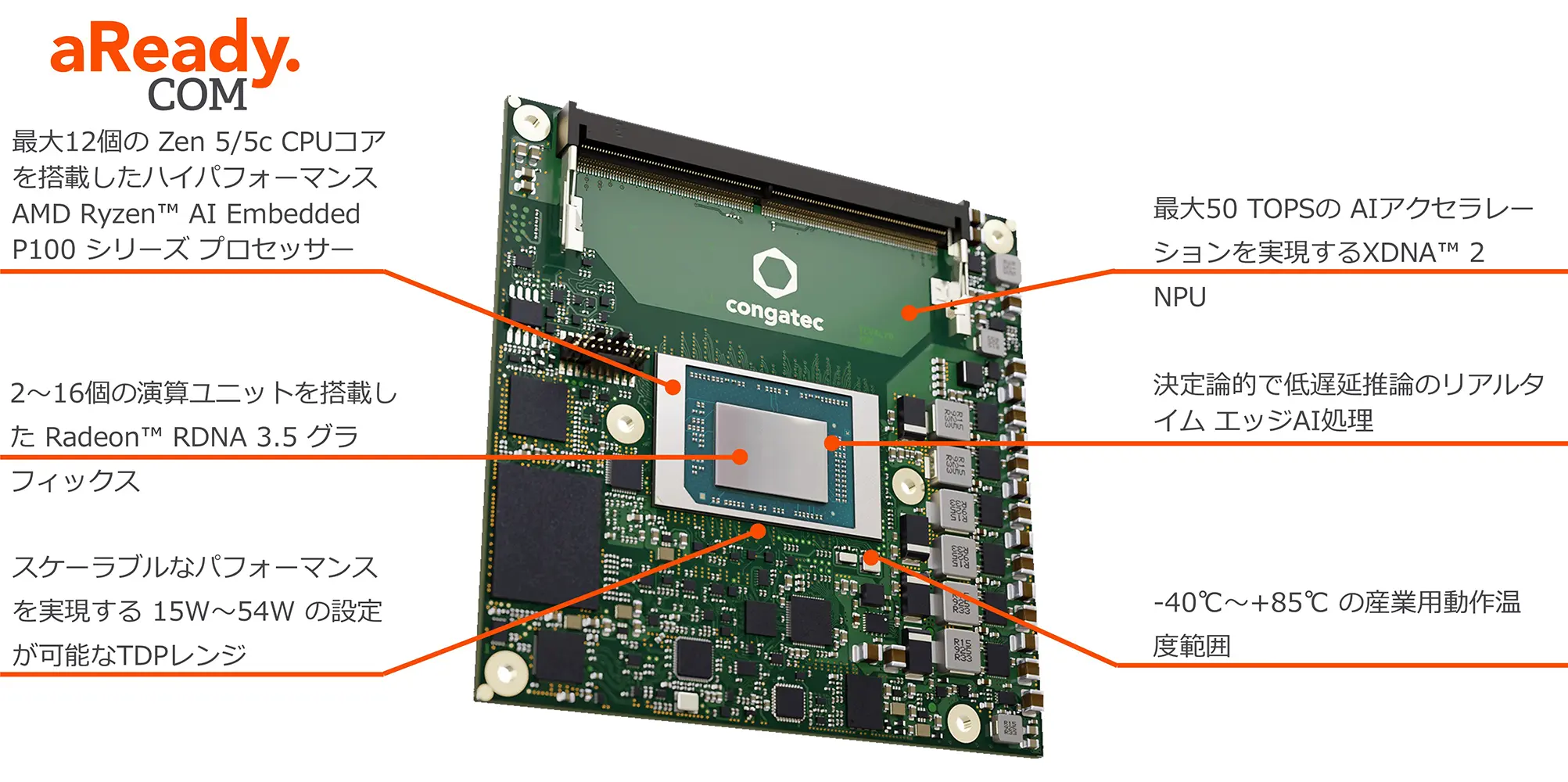
スケーラブルなエッジAIパフォーマンス
最大50 TOPSのAIパフォーマンスを実現する AMD Ryzen™ AI Embedded P100 プロセッサーは、インダストリアル オートメーションやメディカル テクノロジー、マシンビジョン、スマートシティ インフラ、プロゲーミングなど、AIを活用したエッジアプリケーションに最適です。 CPUとGPU、NPUを単一のエネルギー効率の高いシステム・オン・チップ(SoC)に統合することで、クラウド接続を必要とせずにエッジにおいてリアルタイムAI処理を直接実行することができます。 これにより、レイテンシが低減され、データをエッジで直接処理できるため情報セキュリティが向上します。
先進的な Zen 5/5c アーキテクチャーをベースとする最大12個の CPUコアを搭載した AMD Ryzen™ AI Embedded P100 プロセッサーは、エッジコンピューティングにおけるスケーラブルな x86パフォーマンスの新たなベンチマークを確立します。 AMDは、要求の厳しいワークロード向けのハイパフォーマンスコアと、負荷の低い処理やバックグラウンド処理の消費電力を削減する低消費電力で効率的なコアを組み合わせています。 特筆すべきは、両方のコアが同じマイクロアーキテクチャーに基づいて構築されている点です。
これは、すべてのコアが Zen 5 の全機能セットを提供することを意味します。 主な違いは最大コア周波数で、組込みアプリケーションにいくつかのアドバンテージをもたらします。 すべてのコアが同じ実行環境であり命令は同じように処理されるため、タイミングが重要なリアルタイム アプリケーションのプログラミングが簡素化されます。 OSはCPU中心のタスクに対して、均質なコンピューティング リソースプールとして認識されるため、タスク スケジューリングにおいて異なるコアタイプ間での複雑なハンドシェイクは不要です。 さらに、このアプローチは、AMD Ryzen Embedded P100 シリーズの優れた電力スケーラビリティの理由の一つとなっています。
AMDの内蔵 XDNA™ 2 NPU は、最大50 TOPSのAIパフォーマンスを提供し、低遅延のAI推論を実現します。 これにより、コンピュータービジョンや異常検知、光学文字認識(OCR)、リアルタイムのデータ分析といった要求の厳しい AIワークロードをエッジデバイス上でローカルに実行することができます。 クラウド接続の機器とは異なり、ローカル処理によって高い確定的動作を実現します。
コストの最適化からハイパフォーマンス組込みエッジ設計まで
15~54W の設定が可能な TDPレンジにより、パッシブ冷却システムからハイパフォーマンス プラットフォームまでスケーラブルな設計が可能で、追加の AIアクセラレーター カードの必要性がなくなり、システム全体の設計が簡素化されます。
CPU や GPU、NPUの機能を1つの SoC に統合し、TDPを 15W から 54W まで設定可能にしたことで、開発者は、パッシブ冷却方式で SWaP-C(サイズ、重量、消費電力、コスト)を最適化したシステムからハイパフォーマンスのエッジプラットフォームまで、さまざまな設計を単一のプラットフォームで実現することができます。 これにより、設計の手間と部品コストを削減しながら、合理化されたコスト効率の高い設計を維持することができます。
ファクト、機能、利点
| ファクト | 機能 | 利点 |
|---|---|---|
| ヘテロジニアス コンピューティング アーキテクチャー | 最大12個の Zen 5/5c CPUコアと Radeon™ RDNA 3.5 グラフィックス、および最大50 TOPS の性能を持つ内蔵 XDNA™ 2 NPUを1つの SoCに搭載. | 個別のアクセラレーターを使用せずに、要求の厳しいエッジAIワークロードを処理し、サイズ、重量、消費電力、システムコスト(SWaP-C)を削減しながらパフォーマンスを最適化します。 |
| 先進的な AMD Zen 5/5c アーキテクチャー | パフォーマンスが最適化された Zen 5 コアと低消費電力 Zen 5c 高密度コアは、まったく同じマイクロアーキテクチャーを使用. | 同一の実行環境では、設計者が同じ命令セットを使用できるため、リアルタイム アプリケーションのプログラミングが簡素化されます。 さらに、タスク スケジューリングにおいて、異なるコアタイプ間での複雑なハンドシェイクが不要になります。 |
| RDNA™ 3.5 GPU | 最大4台の独立したディスプレイに対応するパワフルな表示およびグラフィック機能 | 高いI/O帯域幅により、没入型HMIコンセプトやデジタルサイネージ、マルチディスプレイの産業用アプリケーションを実現します。 さらに、高いフレームレートにより、スケーラブルでコストを最適化した組込みプラットフォームを必要とする、デジタルサイネージやゲームなどのパワフルなエンターテイメント アプリケーションの実現が可能になります。 |
| XDNA™ 2 NPU | 最大50 TOPSのAI処理性能 | 内蔵の XDNA™ 2 NPU は、最大50 TOPS のAIパフォーマンスを提供し、低遅延のAI推論を実現します。 これにより、コンピュータービジョンや異常検知、光学文字認識(OCR)、リアルタイムのデータ分析といった要求の厳しい AIワークロードをエッジデバイス上でローカルに実行することができます。 クラウド接続の機器とは異なり、ローカル処理によって高い確定的動作を実現します。 |
| 豊富なI/Oセット | 最大8レーンの x1 PCIe Gen 4 | 多数のシングル PCIeレーンは、多数のペリフェラルを実装する必要のある I/Oリッチなアプリケーションに最適です。 例えば、試験・計測の分野では、キャリアボード上に個別の PCIeスイッチを実装しなくても、センサーフュージョンやデジタルツイン用のさまざまなインターフェース カードを接続できるため、システム全体の設計が簡素化されます。 |
| 産業グレードの堅牢性 | -40℃~+85℃ の産業用温度範囲に対応し、長期供給 | 過酷な屋外環境や産業環境向けの堅牢なシステム設計を支援し、耐熱性を向上させます。 平均故障間隔(MTBF)を改善し、メンテナンスコストを削減するとともに、システム全体の寿命を延ばし、総所有コスト(TCO)を最小限に抑えます。 長期供給性と組み合わせることで、定期的かつコストのかかる再設計を回避し、特にメディカルや航空宇宙産業の認証済みアプリケーションにおいて、投資に対する高い安全性を提供します。 |
| プログラム可能な TDP コンフィグレーション | 15W~54W の高いスケーラビリティ | ファンレスの密閉システムからハイパフォーマンスのアクティブ冷却プラットフォームまで、パフォーマンスの拡張が可能です。 1つの組込みコンピューティング プラットフォーム上での完全な製品ファミリーの設計、あるいはさまざまなアプリケーションの設計を簡素化し、初度エンジニアリング(NRE)の労力と総所有コスト(TCO)を最小限に抑えて投資収益率を改善します。 |
代表的なアプリケーション分野
モバイル メディカルイメージング装置
装置に実装されたAIは、GPUによる可視化と NPUベースの画像強調や分析を組み合わせることで、超音波診断やその他のモバイル イメージングシステムを高速化し、より迅速なポイントオブケア診断を可能にします。
産業用マシンビジョン
統合された CPU と NPU の性能により、リアルタイムの品質検査や異常検知、光学文字認識が可能になり、生産効率の向上と廃棄物の削減を実現します。
交通監視とスマートシティ
AIベースの画像認識は、インテリジェントな交通モニターや事故検知、およびデータ分析をサポートし、産業用温度範囲のサポートにより、過酷な路側環境でも信頼性の高い動作を保証します。
プロフェッショナル ゲーミングシステム
ハイパフォーマンスの内蔵グラフィックスは、最新のスロットマシンなどの先進的なゲームおよびエンターテイメント システムに、没入感のあるビジュアル体験を提供します。
AI搭載の POSシステム
AIとグラフィックス機能を統合することで、インテリジェントな顧客分析や自動レジ機能、ダイナミックなデジタルサイネージなど、小売業向けアプリケーションを拡張します。
ロボティクスと自律システム
決定論的で低遅延のエッジAI処理により、クラウド接続に依存することなく、ロボティクスおよび自律プラットフォームにおけるリアルタイムでの認識や位置特定、意思決定が可能になります。


